- 基本概念
- 文字コードの問題点
- 文字コードの問題点を解決するために
文字コードはコンピュータ上で文字(テキスト)を利用するために与えられるバイト(byte)表現です。
もともとコンピューターは「0」か「1」の2進数で情報がやり取りされているため、人間が使えるように文字(英語、日本語他)を表示しなければならないことから文字コードが生まれてきました。
英数字(ABCDE~XYZ、0~9)は36文字であるため、1バイト(256文字分収録可能)で収録可能です。
しかし、漢字やカタカナとひらがなが存在する日本語は1バイトでは収録できません。
そのため、2バイト(65536文字分)の文字コードを使いこの問題を解決しました。
ですが、独自に文字コードを作ったためShift_JISやEUC-JPなどの文字コードが生まれてしまいました。
それぞれ互換性がないので文字化けしてしまう問題が生じています。
文字化けすると何が書かれていたのかさっぱりわかりません。
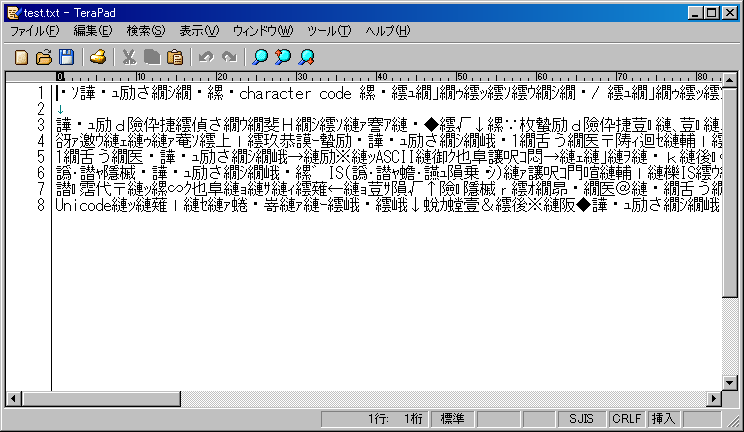
文字化けの問題を解決するために、世界の主要な2バイト文字をすべてカバーする統一規格「Unicode」が作られています。日本語や中国語、韓国語も「Unicode」であれば文字化けせずに表現可能です。
当サイトは、Unicodeの文字コード「UTF-8」をそうした理由で利用しています。
UTF-8でなくとも、使用する文字コードを統一することをおすすめします。
- TeraPadでの方法
- TeraPadでの確認法
- TeraPadでの変換法
- Notepad++での方法
- Notepad++での確認法
- Notepad++での変換法
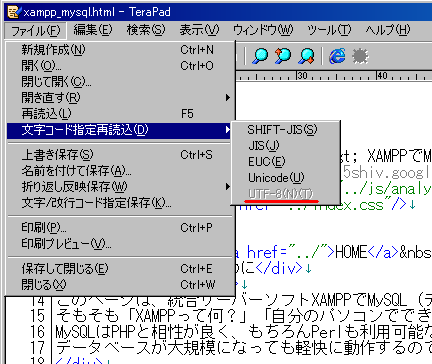
文字コードを確認したいファイルをTeraPadで開いてください。
左上の「ファイル」の「文字コード指定再読込」で確認できます。
図では「UTF-8(N)」(赤下線)で設定されていることがわかります。
左上の「ファイル」の「文字/改行コード指定保存」をクリックします。
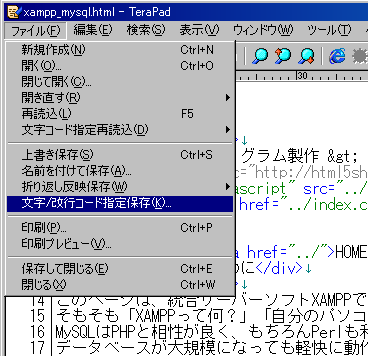
文字/改行コード指定保存のウィンドウが表示されます
「UTF-8」と「UTF-8N」がありますが、図のように「UTF-8N」で保存してください。

保存方法は「UTF-8N」でないと、Perlプログラムで問題が起こることも報告されています。
これはTeraPadの表記の問題でもあります。
TeraPadでは「UTF-8」がBOM(識別コード)ありのUTF-8、「UTF-8N」がBOMなしのUTF-8です。
BOMが厄介な存在なのでTeraPadでは「UTF-8N」を選びます。
実はUTF-8はBOMなしが基本のため、TeraPadの「UTF-8」と他のテキストエディタの「UTF-8」と意味が異なります。ご注意ください。
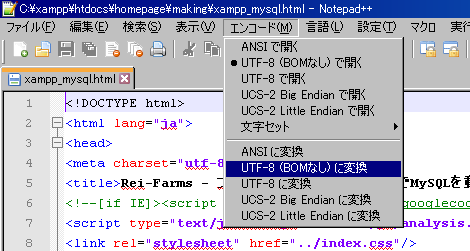
文字コードを確認したいファイルをNotepad++で開いてください。
上の「エンコード」で確認できます。
図では「UTF-8(BOMなし)」で設定されていることがわかります。
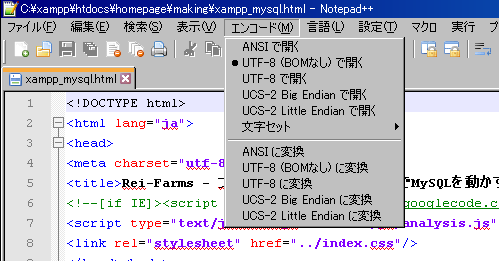
上の「エンコード」に「○○に変換」の項目があります。
そこから「UTF-8(BOMなし)に変換」をクリックします。
保存方法は「UTF-8(BOMなし)」でないと、Perlプログラムで問題が起こることも報告されています。
詳しくはTeraPadでの変換方法をご覧ください。